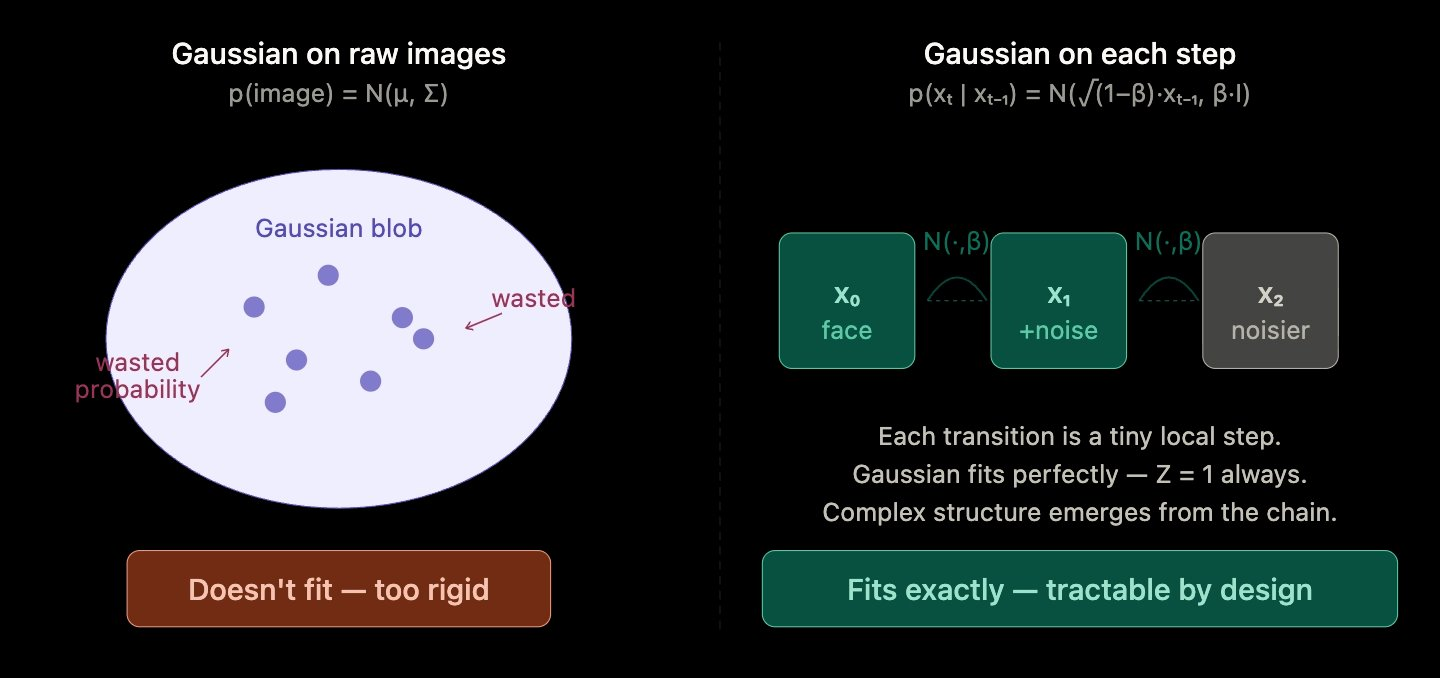
If you've spent any time around generative models, you've probably hit the same confusion I did. People say "a Gaussian can't model the distribution of face images." Then a few pages later, the same people are excitedly describing diffusion models that are built entirely on Gaussians. Which is it?
Both, as it turns out. The trick is that they're talking about Gaussians doing two completely different jobs. Once you see the distinction, a lot of the magic of diffusion stops feeling like magic.
What a Gaussian is actually being asked to do
When someone says "a Gaussian can't model face images," they mean something specific. They mean: if you try to write down
then that single distribution has to cover the entire space of every possible combination of pixels that could form a face. Every lighting condition. Every angle. Every face. A Gaussian is just a bell curve in high dimensions. It has a center and a shape, and that shape is round and convex. It has no way to encode the nonlinear, intricate structure of what makes pixels look like a face versus look like static.
Diffusion never asks a Gaussian to do that. It asks something much, much easier at each step:
"Given that I'm already at a slightly noisy version of this image, what does one tiny step noisier look like?"
That transition, from xt to xt+1, is Gaussian. Not approximately. Not "we'll force it to be." Genuinely, exactly Gaussian by construction. The difference between two images that differ by a tiny sprinkle of independent noise really is normally distributed. The Gaussian is being used to model a small local perturbation, not the global structure of face-space.
The manifold problem
Here's the geometric intuition for why the global approach fails. Real face images don't fill the space of all possible pixel arrays. They cluster on a thin, curved manifold: a low-dimensional surface twisting through a very high-dimensional pixel space. Most points in pixel space are static, noise, garbage. Only a tiny, oddly-shaped sliver contains real faces.
A Gaussian, geometrically, is an ellipsoid. It's round. It's convex. It has no choice but to put probability mass uniformly throughout some symmetric region around its center. If you ask it to "cover" the face manifold, it has to inflate enough to contain that curved ribbon, which means it also has to contain a vast region off the manifold, where no real faces exist at all.
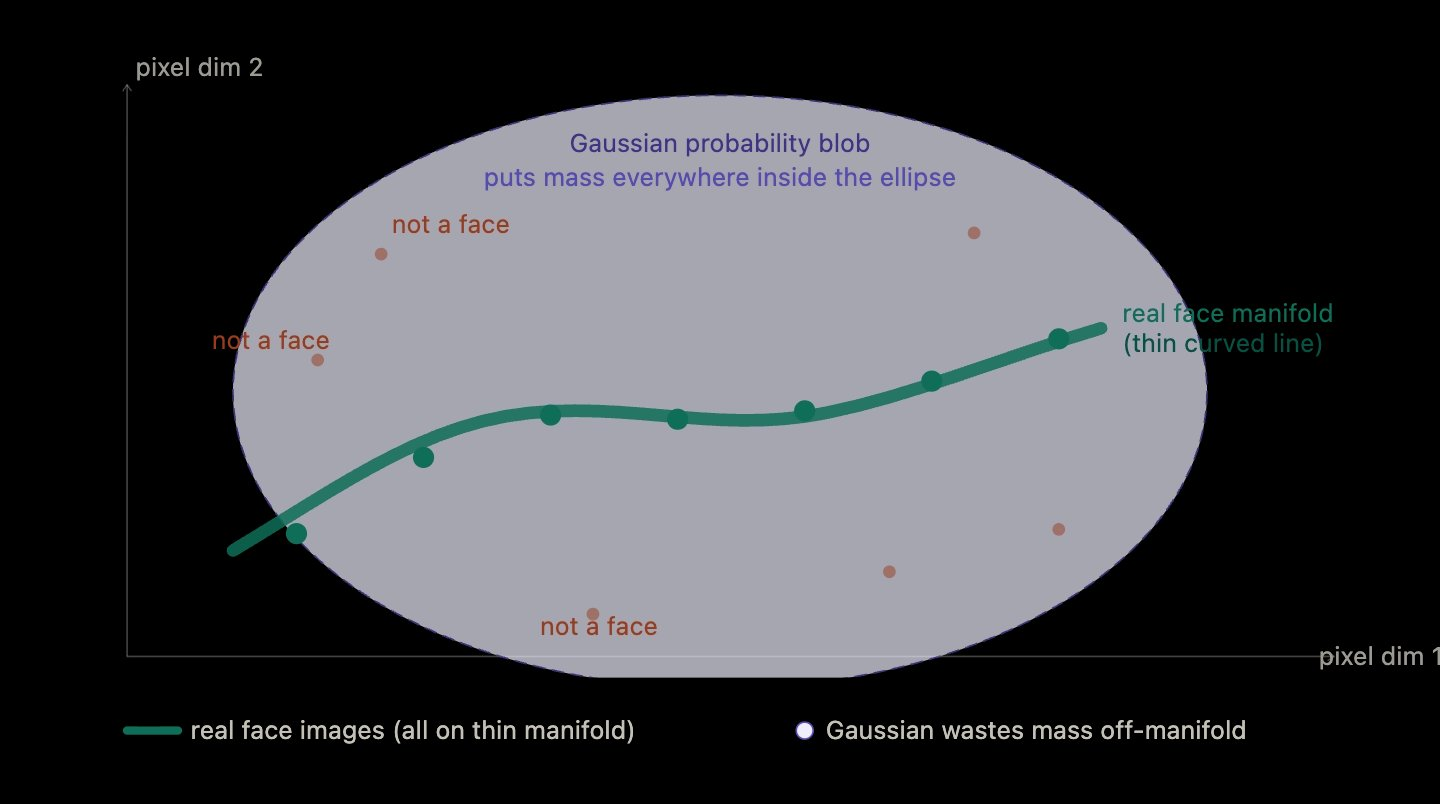
So the Gaussian "fits" only in the loosest sense. It assigns roughly equal probability to real faces and to the void around them. Sample from it and you'll almost certainly get something that isn't a face. That's the failure mode, and it's structural, not a question of training harder.
Why local steps work
Now zoom into a single diffusion step and something genuinely different happens.
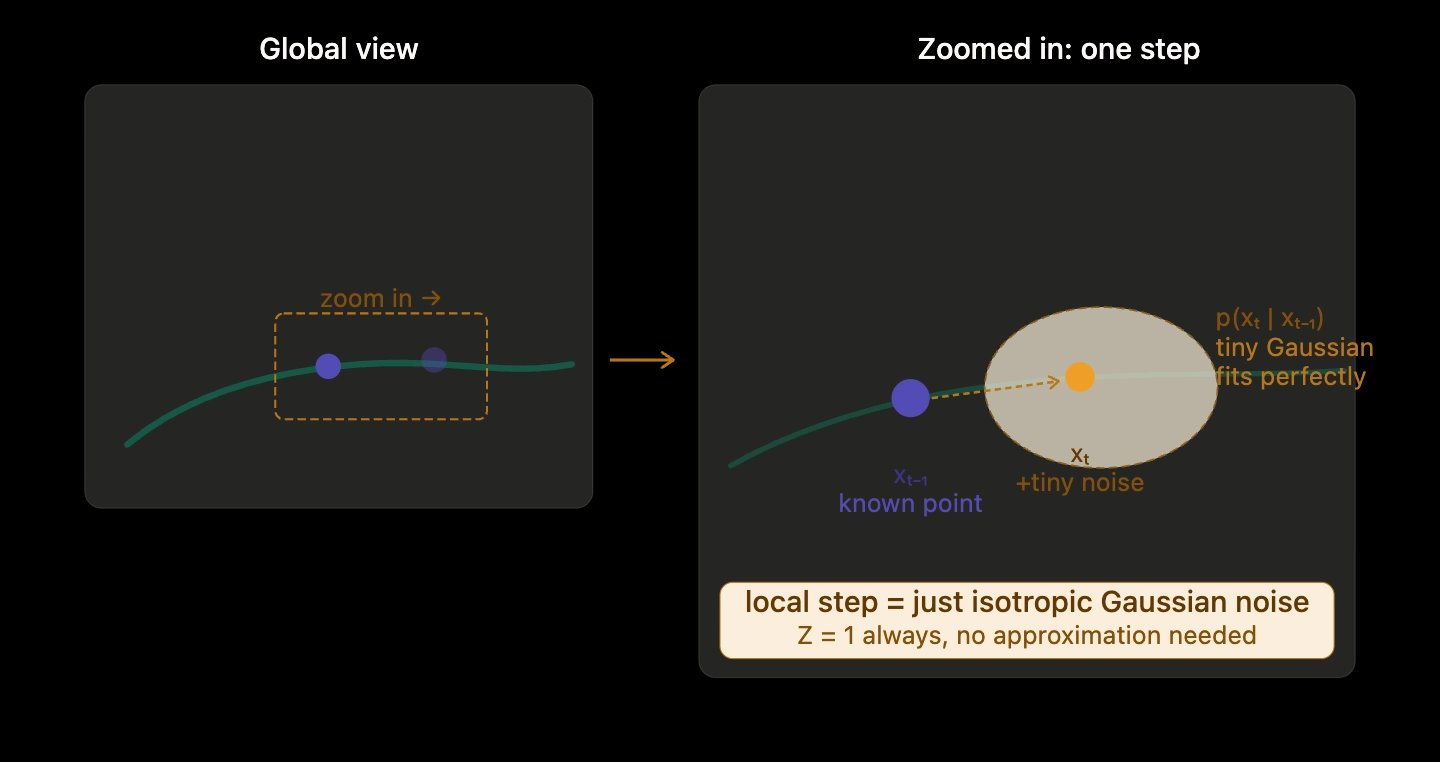
At a single point on the manifold, the question is no longer "where do all faces live?" It's "given you're at xt-1, where does xt land after one tiny nudge of independent noise?"
That really is a small, round, symmetric cloud. A Gaussian. The model doesn't need to know the global shape of the manifold at all. It needs to know "a tiny bit of isotropic noise was added." That's a fact about the forward process, which is defined by the math:
You chose β to be small. You chose the noise to be isotropic. There's nothing to approximate. The Gaussian isn't being forced to describe something complicated; it's describing something that is, by construction, exactly Gaussian.
Global Gaussian: "Describe where all faces live in pixel space" - fails, too rigid.
Local step Gaussian: "Describe where this one point lands after a tiny nudge of noise" - trivially exact, always true.
The complexity of face-space doesn't get baked into any single distribution. It emerges from chaining thousands of these tiny exact steps together. That's the whole insight.
But wait — doesn't a VAE also use a Gaussian?
This is the question that always comes up next, and it's a sharp one. A variational autoencoder also models things with a Gaussian, in a single step, and people don't usually accuse VAEs of being "trivially exact." So what's going on?
The answer is that a VAE and a diffusion model are using Gaussians for different jobs, and only one of them is using the Gaussian honestly.
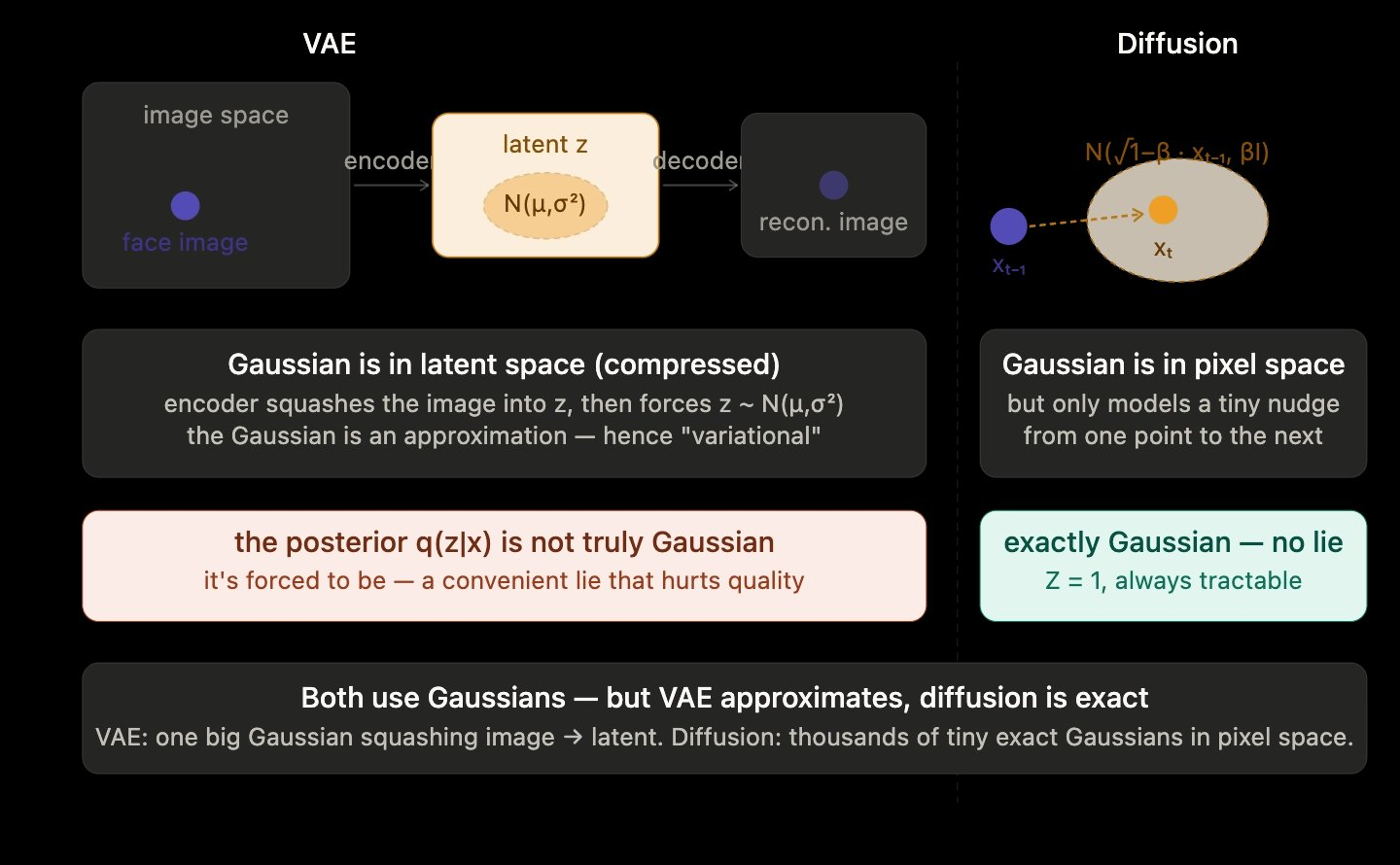
The VAE's Gaussian is an approximation
A VAE's encoder takes a face image x and maps it to a distribution in latent space, q(z|x). The true posterior over latents given the image is almost certainly not Gaussian. It's some complicated, curved shape determined by the geometry of the latent space and the decoder. But the VAE forces it to be Gaussian anyway, because that's what makes the math tractable. That's the "variational" part of "variational autoencoder": you're optimizing a lower bound precisely because the true posterior is intractable.
This is a convenient lie. The model says "I'll pretend the posterior is Gaussian and accept the quality penalty." That's where the famous VAE blurriness comes from. You're approximating a thing that is intrinsically not Gaussian with the closest Gaussian you can find, and the gap between them shows up as fuzziness in the samples.
The diffusion Gaussian is exact
Diffusion's Gaussian is doing the opposite thing. It's not being forced onto an intractable posterior. It's describing a forward process that you designed to be Gaussian. Adding a tiny bit of isotropic Gaussian noise to an image is, by definition, a Gaussian perturbation. There's no approximation. The model isn't pretending. The process really is Gaussian, and the math really does work out exactly.
"The posterior is complicated, but let's pretend it's Gaussian so we can compute."
Approximate. The quality cost shows up as blurry samples.
"Each small noise step is Gaussian by construction."
Exact. No quality penalty from this part of the model.
The VAE trades quality for tractability. Diffusion gets both, by being clever about what it asks the Gaussian to describe. Both models are doing variational inference in some sense, but diffusion sets things up so the variational gap collapses to zero at each step.
The same tool can be a poor fit for one job and a perfect fit for another. The question to ask isn't "is a Gaussian rich enough?" but "what exactly are you asking the Gaussian to describe?"
The takeaway
The confusion around "Gaussians can't model faces, but diffusion uses Gaussians" dissolves once you separate two questions that look the same on the surface but are completely different underneath.
"What's the probability of this image being a face?" requires modeling the global face manifold. A Gaussian is hopelessly inadequate for this. The manifold is curved, sparse, and lives in a tiny corner of pixel space; the Gaussian is round and fat and bleeds probability mass everywhere.
"What's the probability that this slightly noisier image came from this slightly less noisy image, given that I added Gaussian noise?" is a different question entirely. It has a clean closed-form answer. The Gaussian isn't approximating anything; it's just describing the noise you added.
Diffusion's whole trick is to never ask the hard question directly. It decomposes "generate a face" into thousands of "denoise this slightly" steps. Each step is so simple that a Gaussian models it exactly. The hard structure of face-space emerges from the composition, not from any single distribution.
The Gaussian was never the problem. The problem was asking it to describe something it couldn't possibly describe. Once we let it describe only the thing it was always good at — small, local, isotropic perturbations — everything else falls into place. Thanks for reading ✦
Comments